Hive架构
Hive 的数据模型
db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
table:在hdfs中表现所属db目录下一个文件夹
external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表: 删除表后, hdfs上的文件都删了
External外部表: 删除后, hdfs上的文件没有删除, 只是把文件删除了
partition:在hdfs中表现为table目录下的子目录
bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
Hive 架构图

用户接口: CLI、JDBC/ODBC、WebGUI
CLI为shell命令行;JDBC/ODBC是Hive的JAVA实现,与传统数据库JDBC类似;WebGUI是通过浏览器访问Hive。
元数据存储:一般存储在关系型数据库中如 mysql;
Hive 将元数据存储在数据库中。Hive 中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
解释器、编译器、优化器、执行器
解释器、编译器、优化器完成 HQL 查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在 HDFS 中,并在随后有 MapReduce 调用执行。
hive和传统数据库区别
- 需要注意的是传统数据库对表数据检验是 schema on write(写时模式)而 Hive 在 load时不检查数据是否符合 schema 的,hive 遵循的是 schema on read(读时模式),只有在读的时候 hive 才检查、解析具体的数据字段、schema。读时模式的优势是 load data 非常迅速,因为它不需要读取数据进行解析,仅仅进行文件的复制或者移动。写时模式的优势是提升了查询性能,因为预先解析之后可以对列建立索引并压缩,但这样会花费较多的加载时间。即使为内部表在数据加载时也不解析数据格式,如果数据和模式不匹配,只能在查询时出现 null 才知道不匹配的行。
- hive 具有复杂的数据结构(数组,映射,结构体)
- hive 不支持实时数据处理,对索引的支持较弱。
- hive 不支持行级的插入。
- 延迟高,数据量大,多存储在 hdfs 上。
- 执行为 mapreducer。
- hive 不支持行级操作也不支持事务。
Hive SQl 语句执行过程
Hql写出来以后只是一些字符串的拼接,所以要经过一系列的解析处理,才能最终变成集群上的执行的作业
- Parser:将sql解析为AST(抽象语法树),会进行语法校验,AST本质还是字符串
- Analyzer:语法解析,生成QB(query block)
- Logicl Plan:逻辑执行计划解析,生成一堆Opertator Tree
- Logical optimizer:进行逻辑执行计划优化,生成一堆优化后的Opertator Tree
- Phsical plan:物理执行计划解析,生成tasktree
- Phsical Optimizer:进行物理执行计划优化,生成优化后的tasktree,该任务即是集群上的执行的作业
- 结论:经过以上的六步,普通的字符串sql被解析映射成了集群上的执行任务,最重要的两步是 逻辑执行计划优化和物理执行计划优化(图中红线圈画)
Hive基本操作
创建表
建表语句
1 | CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name |
CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION)
LIKE 允许用户复制现有的表结构,但是不复制数据。
ROW FORMAT DELIMITED [FIELDS TERMINATED BY char][COLLECTION ITEMS TERMINATED BY char] [MAP KEYS TERMINATED BY char][LINES TERMINATED BY char] | SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, …)]
STORED AS SEQUENCEFILE|TEXTFILE|RCFILE 如果文件数据是纯文本,可以使用 STORED AS TEXTFILE(默认)。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
CLUSTERED BY 对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
备注: hive 的join操作只支持等值连接
建表示例
1 | create table student(id int, age int, name string) partitioned by(stat_date string) clustered by(id) sorted by(age) into 2 buckets row format delimited fields terminated by','; |
增加分区示例
1 | alter table student_p add partition(part='a') partition(part='b'); |
数据查询
查询语句
1 | SELECT [ALL | DISTINCT] select_expr, select_expr, ... |
- order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
- sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
- 根据distribute by指定的字段内容将数据分到同一个reducer。
- Cluster by 除了具有Distribute by的功能外,还会对该字段进行排序。因此,常常认为cluster by = distribute by + sort by
查询示例
1 | set mapred.reduce.tasks=4; |
Hive Join操作
1. 语法结构
1 | table1 JOIN table2 [join_condition] |
备注:
Hive 支持等值连接(equality joins)、外连接(outer joins)和(left/right joins)。Hive 不支持非等值的连接,因为非等值连接非常难转化到 map/reduce 任务。另外,Hive 支持多于 2 个表的连接。
left semi join 是 IN/EXISTS 的高效实现
等值join
等值join
1
2
3
4
5SELECT a.* FROM a JOIN b ON (a.id = b.id);
SELECT a.* FROM a JOIN b ON (a.id = b.id AND a.department = b.department);
# 是正确的,然而:
SELECT a.* FROM a JOIN b ON (a.id>b.id)
# 是错误的。可以多于两张表
1
2
3
4
5
6
7
8
9SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2);
# 如果join中多个表的 join key 是同一个,则 join 会被转化为单个 map/reduce 任务,例如:
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c
ON (c.key = b.key1)
# 被转化为单个 map/reduce 任务,因为 join 中只使用了 b.key1 作为 join key。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1)
JOIN c ON (c.key = b.key2)
# 而这一 join 被转化为 2 个 map/reduce 任务。因为 b.key1 用于第一次 join 条件,而 b.key2 用于第二次 join。join时,每次map/reduce任务的逻辑
reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统。这一实现有助于在 reduce 端减少内存的使用量。实践中,应该把最大的那个表写在最后(否则会因为缓存浪费大量内存)。例如:
1
2SELECT a.val, b.val, c.val FROM a
JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)所有表都使用同一个 join key(使用 1 次 map/reduce 任务计算)。Reduce 端会缓存 a 表和 b 表的记 录,然后每次取得一个 c 表的记录就计算一次 join 结果,类似的还有:
1
2SELECT a.val, b.val, c.val FROM a
JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)这里用了 2 次 map/reduce 任务。第一次缓存 a 表,用 b 表序列化;第二次缓存第一次 map/reduce 任务的结果,然后用 c 表序列化。
LEFT,RIGHT 和 FULL OUTER 关键字用于处理 join 中空记录的情况
1
2SELECT a.val, b.val FROM
a LEFT OUTER JOIN b ON (a.key=b.key)对应所有 a 表中的记录都有一条记录输出。输出的结果应该是 a.val, b.val,当 a.key=b.key 时,而当 b.key 中找不到等值的 a.key 记录时也会输出:a.val, NULL
所以 a 表中的所有记录都被保留了,a RIGHT OUTER JOIN b”会保留所有 b 表的记录。
Join 发生在 WHERE 子句之前。如果你想限制 join 的输出,应该在 WHERE 子句中写过滤条件——或是在 join 子句中写。这里面一个容易混淆的问题是表分区的情况:
1
2
3SELECT a.val, b.val FROM a
LEFT OUTER JOIN b ON (a.key=b.key)
WHERE a.ds='2009-07-07' AND b.ds='2009-07-07'会 join a 表到 b 表(OUTER JOIN),列出 a.val 和 b.val 的记录。WHERE 从句中可以使用其他列作为过滤条件。但是,如前所述,如果 b 表中找不到对应 a 表的记录,b 表的所有列都会列出 NULL,包括 ds 列。也就是说,join 会过滤 b 表中不能找到匹配 a 表 join key 的所有记录。这样的话,LEFT OUTER 就使得查询结果与 WHERE 子句无关了。解决的办法是在 OUTER JOIN 时使用以下语法:
1
2
3
4SELECT a.val, b.val FROM a LEFT OUTER JOIN b
ON (a.key=b.key AND
b.ds='2009-07-07' AND
a.ds='2009-07-07')这一查询的结果是预先在 join 阶段过滤过的,所以不会存在上述问题。这一逻辑也可以应用于 RIGHT 和 FULL 类型的 join 中。
Join 是不能交换位置的。
无论是 LEFT 还是 RIGHT join,都是左连接的。
1
2
3SELECT a.val1, a.val2, b.val, c.valFROM a
JOIN b ON (a.key = b.key)
LEFT OUTER JOIN c ON (a.key = c.key)先 join a 表到 b 表,丢弃掉所有 join key 中不匹配的记录,然后用这一中间结果和 c 表做 join。这一表述有一个不太明显的问题,就是当一个 key 在 a 表和 c 表都存在,但是 b 表中不存在的时候:整个记录在第一次 join,即 a JOIN b 的时候都被丢掉了(包括a.val1,a.val2和a.key),然后我们再和 c 表 join 的时候,如果 c.key 与 a.key 或 b.key 相等,就会得到这样的结果:NULL, NULL, NULL, c.val
Hive 表
hive 内部表和外部表区别
- Hive 创建内部表时,会将数据移动到数据仓库指向的路径,hive 管理数据的声明周期,若创建外部表,仅记录数据所在的路径,不会对数据的位置做任何改变。
- 在删除表的时候,内部表的元数据和数据会被一起删除, 外部表只会删除外部表的元数据, 不删除数据,这样外部表相对来说更安全一些,数据组织也更加灵活,方便共享源数据。;
- 对于一些 hive 操作不适应于外部表,比如单个查询语句创建表并向表中插入数据。
- 创建外部表时甚至不需要知道外部数据是否存在,可以把创建数据推迟到创建表之后才进行。
Hive分区
hive 分区的了解
是对 hive 表的一种组织形式,可以加快查询,是一种对表进行粗略划分的机制。使用分区时,在表目录下会有相应的子目录,当查询时若添加了分区谓词,该查询会定位到相应的子目录中进行查询,避免全表扫描,比如日志文件分析,将日志按天存储。分区并不会影响大范围的查询。
外部表也可以分区,具有很好的灵活性,例如
这种灵活性有一个有趣的优点是我们可以使用像 Amazon S3 这样的廉价的存储设备存储旧的数据,同时保持较新的数据到 HDFS 中。例如,每天我们可以使用如下的处理过程将一个月前的旧数据转移到 S3 中。
使用hive分区的注意事项
- 当分区过多且数据很大时,可以使用严格模式,避免触发一个大的 mapreducer 任务。当分区数量过多且数据量较大时,执行宽范围的数据扫描会触发一个很大的 mapreducer 任务,在严格模式下,当 where 中没有分区过滤条件时会禁止执行。
- hive 如果有过多的分区,由于底层是存储在 HDFS 上,HDFS适用于存储大文件而非小文件,因此过多的分区会增加 namenode 负担。
- hive 会转化成 mapreducer,mapreducer 会转化为多个 task,过多的小文件的话,每个文件一个task,每个task 一个 jvm实例,jvm 开启与销毁会降低系统效率。
Hive 分桶
Hive 分桶的理由
- 取样更高效。具体划分桶是将值进行hash,然后除以桶的个数取余,任何一个桶内部是一个随机划分的用户集合。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分上试运行查询,会方便很多。
- 获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接(Map-side join)高效的实现。处理左边表的某个桶的 mapper 就知道右边表内相匹配的行在对应的桶,这样 mapper 直接就可以在对应的右边表的桶获取数据进行 join。并不一定要求两个表必须有相同的桶的个数,倍数也行。
Hive 锁机制
锁机制
Hive 内部定义了两种类型的锁:
- 共享锁(Share)
- 互斥锁(Exclusive)
不同锁之间的兼容性入下面表格:

锁的基本机制是:
- 元信息和数据的变更需要互斥锁
- 数据的读取需要共享锁
根据这个机制,Hive 的一些场景操作对应的锁级别如下:

Hive 锁在 zookeeper 上会对应 ephemeral 的节点,避免释放锁失败导致死锁
调试锁
可以通过下面命令查看某个表或者分区的锁
- SHOW LOCKS ;
- SHOW LOCKS EXTENDED;
- SHOW LOCKS PARTITION ();
- SHOW LOCKS PARTITION () EXTENDED;
关闭锁机制
可以通过设置 hive.support.concurrency=fasle 来解决
关闭锁机制会造成下面影响:
- 并发读写同一份数据时,读操作可能会随机失败
- 并发写操作的结果在随机出现,后完成的任务覆盖之前完成任务的结果
- SHOW LOCKS, UNLOCK TABLE 会报错
HIVE SQL优化
优化思路
- 尽早尽量过滤数据,减少每个阶段的数据量
- 减少job数
- 解决数据倾斜问题
Hive SQL 优化手段
1.列裁剪:
例如某表有a,b,c,d,e五个字段,但是我们只需要a和b,那么请用select a,b from table 而不是select * from table
2.分区裁剪:
在查询的过程中减少不必要的分区,即尽量指定分区
3.利用hive的优化机制减少job数:
不论是外关联outer join还是内关联inner join,如果join的key相同,不管有多少表,都会合并为一个MapReduce任务:
1 | select a.val,b.val,c.val from a JOIN b ON (a.key = b.key1) JOIN c ON (c.key2 = b.key1) ----一个job |
4.善用multi-insert:
1 | #查询了两次a |
5.善用union all:
不同表的union all相当于multi inputs,同一表的union all相当于map一次输出多条
6.避免笛卡尔积:关联的时候一定要写关联条件
7.join前过滤掉不需要的数据
1 | #hive0.12之前,会先把a全部数据和b的全部数据进行了关联,然后再筛选条件,0.12之后做了优化 |
8.小表放前大表放后
在编写带有join的代码语句时,应该将条目少的表/子查询放在join操作符的前面
因为在Reduce阶段,位于join操作符左边的表会先被加载到内存,载入条目较少的表可以有效的防止内存溢出(OOM)。所以对于同一个key来说,对应的value值小的放前面,大的放后面
9.在map阶段进行join
join阶段有两种,一种是在map阶段进行的,一种是在reduce阶段进行的。当小表和大表进行join时,尽量采用mapjoin,即在map端完成,尽早结合数据,使reduce端接收数据量减少。同时可以避免小表与大表join产生的数据倾斜。
如果一个表特别小,推荐用mapjoin;如果不是,我们一般用reduce join
MAPJOIN写法:
1 | select /*+ MAPJOIN(b) */ a.value,b.value from a join b on a.key=b.key |
10.hive0.13之前实现IN和EXISTS
LEFT SEMI JOIN是IN和EXISTS的一种高效实现,在hive0.13之前是不支持IN和EXISTS的
1 | 1.select a.key,a.value from a where a.key in (select b.key from b)(hive0.13前不支持) |
LEFT SEMI JOIN产生的数据不会重复。
11.使用动态分区
1 | set hive.exec.dynamic.partition=true; |
12.union all优化
hive0.13之前不支持union all直接放外层,必须外层套一个查询,例如:
1 | select key,value from a |
是不支持的。
hive对union all的优化只局限于非嵌套查询。
1 | select * from( |
不同表太多的union all,不推荐使用。可以写在中间表的不同分区里,然后再进行union all
13.尽量避免使用distinct
尽量避免使用distinct进行重排,特别是大表,容易产生数据倾斜(key一样在一个reduce处理)。使用group by替代
1 | select distinct key from a |
14.排序优化
只有order by产生的结果是全局有序的,可以根据实际场景进行选择排序
- order by实现全局排序,一个reduce实现,由于不能并发执行,所以效率低
- sort by实现部分有序,单个reduce的输出结果是有序的,效率高,通常与distribute by一起使用(distribute by 关键词可以指定map到reduce的key分发)
- cluster by col1等价于distribute by col1 sort by col1,但不能指定排序规则
15.使用explain dependency查看sql实际扫描多少分区
Hive 分析函数和窗口函数
1. 分析函数:用于等级、百分点、n分片等
Ntile 是Hive很强大的一个分析函数。
可以看成是:它把有序的数据集合 平均分配 到 指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。
语法是:
ntile (num) over ([partition_clause] order_by_clause) as your_bucket_num
然后可以根据桶号,选取前或后 n分之几的数据。
例子:
给了用户和每个用户对应的消费信息表, 计算花费前50%的用户的平均消费;
1 | -- 把用户和消费表,按消费下降顺序平均分成2份 |
Rank,Dense_Rank, Row_Number
SQL很熟悉的3个组内排序函数了。语法一样:
R() over (partion by col1… order by col2… desc/asc)
1 | select |
如上图所示,rank 会对相同数值,输出相同的序号,而且下一个序号不间断;
dense_rank 会对相同数值,输出相同的序号,但下一个序号,间断
row_number 会对所有数值输出不同的序号,序号唯一连续;
2. 窗口函数 Lag, Lead, First_value,Last_value
Lag, Lead
LAG(col,n,DEFAULT) 用于统计窗口内往上第n行值
LEAD(col,n,DEFAULT) 用于统计窗口内往下第n行值, 与LAG相反
– 组内排序后,向后或向前偏移
– 如果省略掉第三个参数,默认为NULL,否则补上。
1 | select |
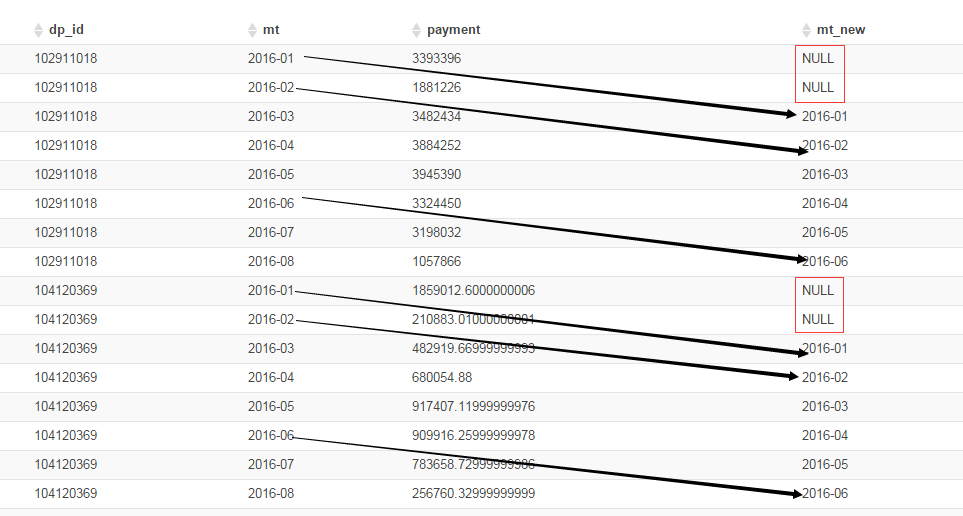
– 组内排序后,向后或向前偏移
– 如果省略掉第三个参数,默认为NULL,否则补上。
1 | select |

FIRST_VALUE, LAST_VALUE
first_value: 取分组内排序后,截止到当前行,第一个值
last_value: 取分组内排序后,截止到当前行,最后一个值
1 | -- FIRST_VALUE 获得组内当前行往前的首个值 |

Hive 存储格式
TextFile、SequenceFile、RCfile 、ORCfile各有什么区别
1、TextFile
默认格式,存储方式为行存储,数据不做压缩,磁盘开销大,数据解析开销大。可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,压缩后的文件不支持split,Hive不会对数据进行切分,从而无法对数据进行并行操作。并且在反序列化过程中,必须逐个字符判断是不是分隔符和行结束符,因此反序列化开销会比SequenceFile高几十倍。
2、SequenceFile
SequenceFile是Hadoop API提供的一种二进制文件支持,存储方式为行存储,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
优势是文件和hadoop api中的MapFile是相互兼容的
3、RCFile
存储方式:数据按行分块,每块按列存储。结合了行存储和列存储的优点:
首先,RCFile 保证同一行的数据位于同一节点,因此元组重构的开销很低;
其次,像列存储一样,RCFile 能够利用列维度的数据压缩,并且能跳过不必要的列读取;
4、ORCFile
存储方式:数据按行分块 每块按照列存储。
压缩快、快速列存取。
效率比rcfile高,是rcfile的改良版本。
5、Parquet
总结:
相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。
数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势。
