一、部署模式
Flink 支持使用多种部署模式来满足不同规模应用的需求,常见的有单机模式,Standalone Cluster 模式,同时 Flink 也支持部署在其他第三方平台上,如 YARN,Mesos,Docker,Kubernetes 等。以下主要介绍其单机模式和 Standalone Cluster 模式的部署。
二、单机模式
单机模式是一种开箱即用的模式,可以在单台服务器上运行,适用于日常的开发和调试。具体操作步骤如下:
2.1 安装部署
1. 前置条件
Flink 的运行依赖 JAVA 环境,故需要预先安装好 JDK,具体步骤可以参考:Linux 环境下 JDK 安装
2. 下载 & 解压 & 运行
Flink 所有版本的安装包可以直接从其官网进行下载,这里我下载的 Flink 的版本为 1.9.1 ,要求的 JDK 版本为 1.8.x +。 下载后解压到指定目录:
1 | tar -zxvf flink-1.9.1-bin-scala_2.12.tgz -C /usr/app |
不需要进行任何配置,直接使用以下命令就可以启动单机版本的 Flink:
1 | bin/start-cluster.sh |
3. WEB UI 界面
Flink 提供了 WEB 界面用于直观的管理 Flink 集群,访问端口为 8081:
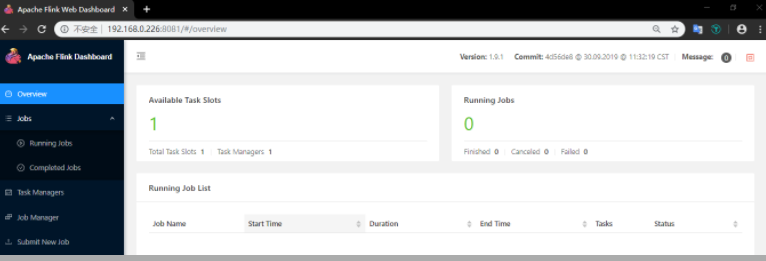
Flink 的 WEB UI 界面支持大多数常用功能,如提交作业,取消作业,查看各个节点运行情况,查看作业执行情况等,大家可以在部署完成后,进入该页面进行详细的浏览。
2.2 作业提交
启动后可以运行安装包中自带的词频统计案例,具体步骤如下:
1. 开启端口
1 | nc -lk 9999 |
2. 提交作业
1 | bin/flink run examples/streaming/SocketWindowWordCount.jar --port 9999 |
该 JAR 包的源码可以在 Flink 官方的 GitHub 仓库中找到,地址为 :SocketWindowWordCount ,可选传参有 hostname, port,对应的词频数据需要使用空格进行分割。
3. 输入测试数据
1 | a a b b c c c a e |
4. 查看控制台输出
可以通过 WEB UI 的控制台查看作业统运行情况:
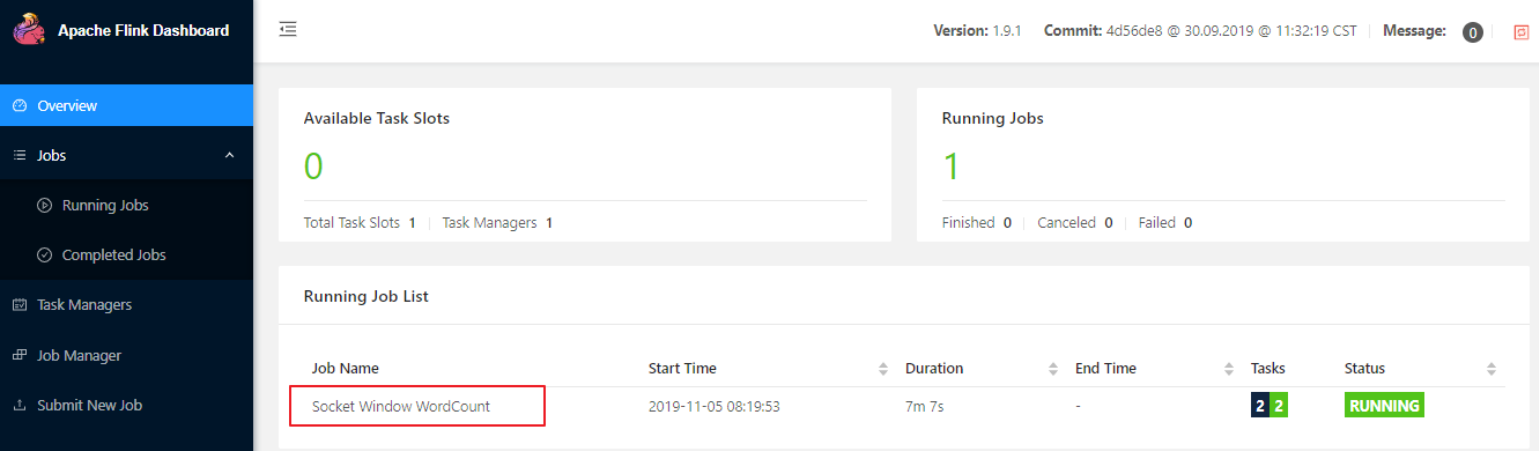
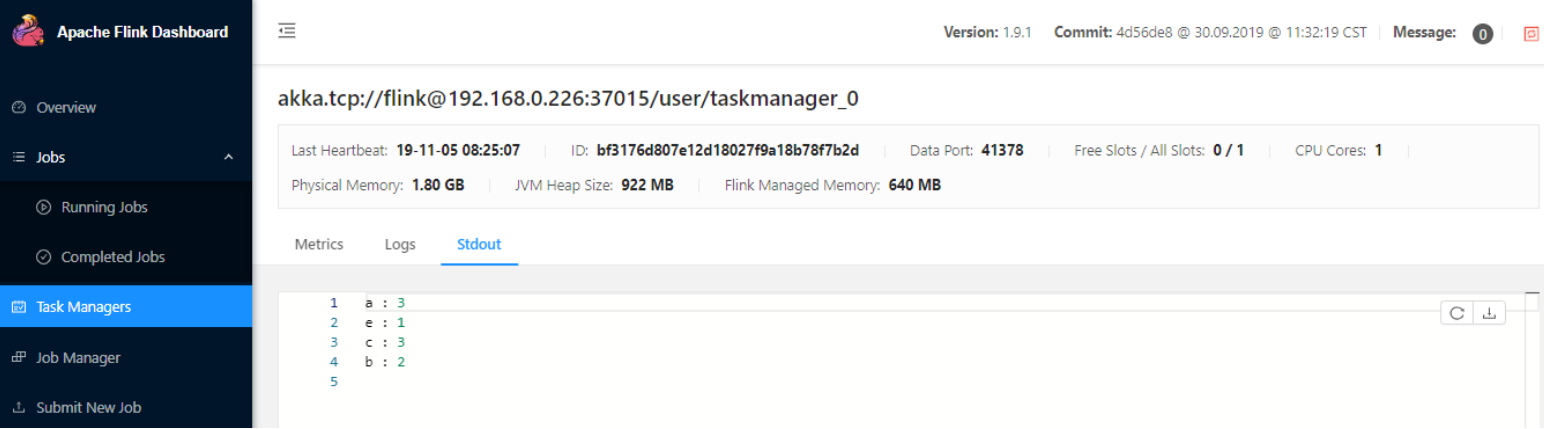
也可以通过 WEB 控制台查看到统计结果:
2.3 停止作业
可以直接在 WEB 界面上点击对应作业的 Cancel Job 按钮进行取消,也可以使用命令行进行取消。使用命令行进行取消时,需要先获取到作业的 JobId,可以使用 flink list 命令查看,输出如下:
1 | [root@hadoop001 flink-1.9.1]# ./bin/flink list |
获取到 JobId 后,就可以使用 flink cancel 命令取消作业:
1 | bin/flink cancel ba2b1cc41a5e241c32d574c93de8a2bc |
2.4 停止 Flink
命令如下:
1 | bin/stop-cluster.sh |
三、Standalone Cluster
Standalone Cluster 模式是 Flink 自带的一种集群模式,具体配置步骤如下:
3.1 前置条件
使用该模式前,需要确保所有服务器间都已经配置好 SSH 免密登录服务。这里我以三台服务器为例,主机名分别为 hadoop001,hadoop002,hadoop003 , 其中 hadoop001 为 master 节点,其余两台为 slave 节点,搭建步骤如下:
3.2 搭建步骤
修改 conf/flink-conf.yaml 中 jobmanager 节点的通讯地址为 hadoop001:
1 | jobmanager.rpc.address: hadoop001 |
修改 conf/slaves 配置文件,将 hadoop002 和 hadoop003 配置为 slave 节点:
1 | hadoop002 |
将配置好的 Flink 安装包分发到其他两台服务器上:
1 | scp -r /usr/app/flink-1.9.1 hadoop002:/usr/app |
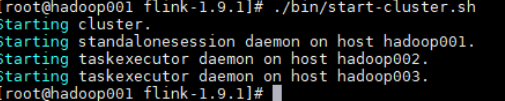
在 hadoop001 上使用和单机模式相同的命令来启动集群:
1 | bin/start-cluster.sh |
此时控制台输出如下:
启动完成后可以使用 Jps 命令或者通过 WEB 界面来查看是否启动成功。
3.3 可选配置
除了上面介绍的 jobmanager.rpc.address 是必选配置外,Flink h还支持使用其他可选参数来优化集群性能,主要如下:
- jobmanager.heap.size:JobManager 的 JVM 堆内存大小,默认为 1024m 。
- taskmanager.heap.size:Taskmanager 的 JVM 堆内存大小,默认为 1024m 。
- taskmanager.numberOfTaskSlots:Taskmanager 上 slots 的数量,通常设置为 CPU 核心的数量,或其一半。
- parallelism.default:任务默认的并行度。
- io.tmp.dirs:存储临时文件的路径,如果没有配置,则默认采用服务器的临时目录,如 LInux 的
/tmp目录。
更多配置可以参考 Flink 的官方手册:Configuration
4.3 常见异常
如果进程没有启动,可以通过查看 log 目录下的日志来定位错误,常见的一个错误如下:
1 | 2019-11-05 09:18:35,877 INFO org.apache.flink.runtime.entrypoint.ClusterEntrypoint |
可以看到是因为在 classpath 目录下找不到 Hadoop 的相关依赖,此时需要检查是否在环境变量中配置了 Hadoop 的安装路径,如果路径已经配置但仍然存在上面的问题,可以从 Flink 官网下载对应版本的 Hadoop 组件包:

下载完成后,将该 JAR 包上传至所有 Flink 安装目录的 lib 目录即可。
四、On Yarn
Yarn的简介:
- ResourceManager
ResourceManager 负责整个集群的资源管理和分配,是一个全局的资源管理系统。 NodeManager 以心跳的方式向 ResourceManager 汇报资源使用情况(目前主要是 CPU 和内存的使用情况)。RM 只接受 NM 的资源回报信息,对于具体的资源处理则交给 NM 自己处理。 - NodeManager
NodeManager 是每个节点上的资源和任务管理器,它是管理这台机器的代理,负责该节点程序的运行,以及该节点资源的管理和监控。YARN 集群每个节点都运行一个NodeManager。
NodeManager 定时向 ResourceManager 汇报本节点资源(CPU、内存)的使用情况和Container 的运行状态。当 ResourceManager 宕机时 NodeManager 自动连接 RM 备用节点。
NodeManager 接收并处理来自 ApplicationMaster 的 Container 启动、停止等各种请求。 - ApplicationMaster
负责与 RM 调度器协商以获取资源(用 Container 表示)。
将得到的任务进一步分配给内部的任务(资源的二次分配)。
与 NM 通信以启动/停止任务。
监控所有任务运行状态,并在任务运行失败时重新为任务申请资源以重启任务
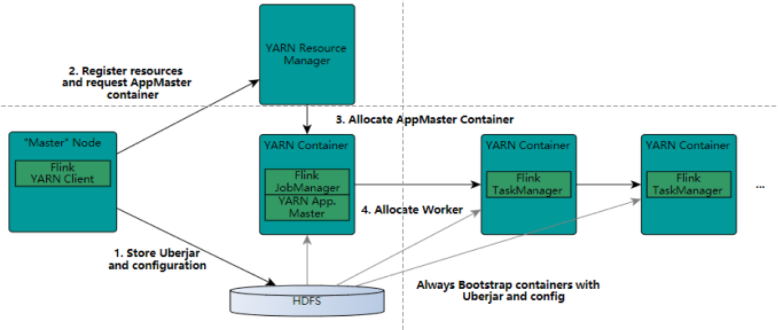
Flink on yarn 集群启动步骤
- 步骤1 用户向YARN中提交应用程序,其中包括ApplicationMaster程序、启动ApplicationMaster的命令、用户程序等。
- 步骤2 ResourceManager为该应用程序分配第一个Container,并与对应的Node-Manager通信,要求它在这个Container中启动应用程序的ApplicationMaster。
- 步骤3 ApplicationMaster首先向ResourceManager注册,这样用户可以直接通过ResourceManager查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
- 步骤4 ApplicationMaster采用轮询的方式通过RPC协议向ResourceManager申请和领取资源。
- 步骤5 一旦ApplicationMaster申请到资源后,便与对应的NodeManager通信,要求它启动任务。
- 步骤6 NodeManager为任务设置好运行环境(包括环境变量、JAR包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 步骤7 各个任务通过某个RPC协议向ApplicationMaster汇报自己的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。 在应用程序运行过程中,用户可随时通过RPC向ApplicationMaster查询应用程序的当前运行状态。
- 步骤8 应用程序运行完成后,ApplicationMaster向ResourceManager注销并关闭自己
on yarn 集群部署
设置Hadoop环境变量:
1 | [root@hadoop2 flink-1.7.2]# vi /etc/profile |
bin/yarn-session.sh -h 查看使用方法:

在启动的是可以指定TaskManager的个数以及内存(默认是1G),也可以指定JobManager的内存,但是JobManager的个数只能是一个
我们开启动一个YARN session:
1 | ./bin/yarn-session.sh -n 4 -tm 8192 -s 8 |
上面命令启动了4个TaskManager,每个TaskManager内存为8G且占用了8个核(是每个TaskManager,默认是1个核)。在启动YARN session的时候会加载conf/flink-config.yaml配置文件,我们可以根据自己的需求去修改里面的相关参数.
YARN session启动之后就可以使用bin/flink来启动提交作业:
例如:
1 | ./bin/flink run -c com.demo.wangzhiwu.WordCount $DEMO_DIR/target/flink-demo-1.0.SNAPSHOT.jar --port 9000 |
flink run的用法如下:
1 | 用法: run [OPTIONS] <jar-file> <arguments> |
使用run 命令向yarn集群提交一个job。客户端可以确定jobmanager的地址。当然,你也可以通过-m参数指定jobmanager。jobmanager的地址在yarn控制台上可以看到。
值得注意的是:
上面的YARN session是在Hadoop YARN环境下启动一个Flink cluster集群,里面的资源是可以共享给其他的Flink作业。我们还可以在YARN上启动一个Flink作业。这里我们还是使用./bin/flink,但是不需要事先启动YARN session:
1 | ./bin/flink run -m yarn-cluster -yn 2 ./examples/batch/WordCount.jar \ |
上面的命令同样会启动一个类似于YARN session启动的页面。其中的-yn是指TaskManager的个数,必须要指定。
后台运行 yarn session
如果你不希望flink yarn client一直运行,也可以启动一个后台运行的yarn session。使用这个参数:-d 或者 –detached
在这种情况下,flink yarn client将会只提交任务到集群然后关闭自己。注意:在这种情况下,无法使用flink停止yarn session。
必须使用yarn工具来停止yarn session
1 | yarn application -kill <applicationId> |
flink on yarn的故障恢复
flink 的 yarn 客户端通过下面的配置参数来控制容器的故障恢复。这些参数可以通过conf/flink-conf.yaml 或者在启动yarn session的时候通过-D参数来指定。
- yarn.reallocate-failed:这个参数控制了flink是否应该重新分配失败的taskmanager容器。默认是true。
- yarn.maximum-failed-containers:applicationMaster可以接受的容器最大失败次数,达到这个参数,就会认为yarn session失败。默认这个次数和初始化请求的taskmanager数量相等(-n 参数指定的)。
- yarn.application-attempts:applicationMaster重试的次数。如果这个值被设置为1(默认就是1),当application master失败的时候,yarn session也会失败。设置一个比较大的值的话,yarn会尝试重启applicationMaster。
日志文件查看
在某种情况下,flink yarn session 部署失败是由于它自身的原因,用户必须依赖于yarn的日志来进行分析。最有用的就是yarn log aggregation 。启动它,用户必须在yarn-site.xml文件中设置yarn.log-aggregation-enable 属性为true。一旦启用了,用户可以通过下面的命令来查看一个失败的yarn session的所有详细日志。
1 | yarn logs -applicationId <application ID> |
五、Standalone集群高可用性
概述
JobManager 协调每个 Flink 部署。它负责调度和资源管理。
默认情况下,每个 Flink 集群只有一个 JobManager 实例。 这会产生单点故障(SPOF):如果 JobManager 崩溃,则无法提交新作业并且导致运行中的作业运行失败。
使用 JobManager 高可用性模式,可以避免这个问题,从而消除 SPOF。您可以为Standalone和 YARN 集群配置高可用性。
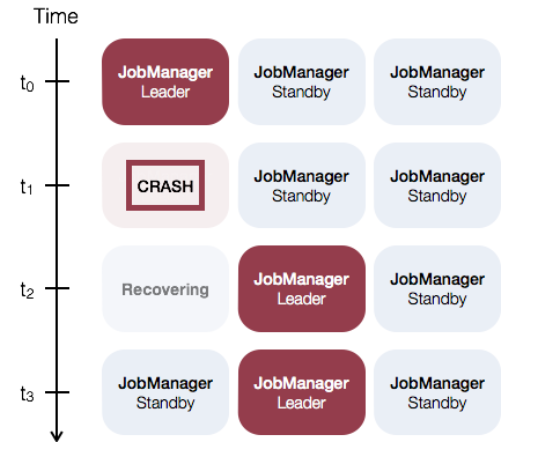
针对 Standalone 集群的 JobManager 高可用性的一般概念是,任何时候都有一个 主 JobManager 和多个备 JobManagers,以便在主节点失败时有备 JobManagers 来接管集群。这保证了没有单点故障,一旦备 JobManager 接管集群,作业就可以正常运行。主备 JobManager 实例之间没有明显的区别。每个 JobManager 都可以充当主备节点。
例如,请考虑以下三个 JobManager 实例的设置:
配置
要启用 JobManager 高可用性,您必须将高可用性模式设置为 zookeeper,配置 zookeeper quorum 将所有 JobManager 主机及其 web UI 端口写入配置文件。
Flink利用 ZooKeeper 在所有正在运行的 JobManager 实例之间进行分布式协调。 ZooKeeper 是独立于 Flink 的服务,通过 Leader 选举和轻量级一致状态存储提供高可靠的分布式协调。
Masters文件 (masters服务器)
要启动HA集群,请在以下位置配置Master文件
- conf/masters:masters文件:masters文件包含启动 jobmanager 的所有主机和 web 用户界面绑定的端口。
1 | jobManagerAddress1:webUIPort1 |
默认情况下,job manager选一个随机端口作为进程随机通信端口。您可以通过 high-availability.jobmanager.port 键修改此设置。此配置接受单个端口(例如50010),范围(50000-50025)或两者的组合(50010,50011,50020-50025,50050-50075)。
配置文件(flink-conf.yaml)
要启动HA集群,请将以下配置键添加到 conf/flink-conf.yaml:
- 高可用性模式(必需):在 conf/flink-conf.yaml 中,必须将高可用性模式设置为zookeeper,以打开高可用模式。或者将此选项设置为工厂类的 FQN,Flink 通过创建 HighAvailabilityServices 实例使用。
1 | high-availability: zookeeper |
- Zookeeper quorum(必需): ZooKeeper quorum 是 ZooKeeper 服务器的复制组,它提供分布式协调服务。
1 | high-availability.zookeeper.quorum:address1:2181[,...],addressX:2181 |
每个 addressX:port 都是一个 ZooKeeper 服务器的ip及其端口,Flink 可以在指定的地址和端口访问zookeeper。
- ZooKeeper root (推荐): ZooKeeper 根节点,在该节点下放置所有集群节点。
1 | high-availability.zookeeper.path.root: /flink |
- ZooKeeper cluster-id(推荐): ZooKeeper的cluster-id节点,在该节点下放置集群的所有相关数据。
1 | high-availability.cluster-id: /default_ns # important: customize per cluster |
重要: 在运行 YARN 或其他群集管理器中运行时,不要手动设置此值。在这些情况下,将根据应用程序 ID 自动生成 cluster-id。 手动设置 cluster-id 会覆盖 YARN 中的自动生成的 ID。反过来,使用 -z CLI 选项指定 cluster-id 会覆盖手动配置。如果在裸机上运行多个 Flink HA 集群,则必须为每个集群手动配置单独的 cluster-id。
- 存储目录(必需): JobManager 元数据保存在文件系统 storageDir 中,在 ZooKeeper 中仅保存了指向此状态的指针。
1 | high-availability.storageDir: hdfs://xxx/flink/recovery |
该storageDir 中保存了 JobManager 恢复状态所需的所有元数据。
配置 master 文件和 ZooKeeper quorum 之后,您可以使用提供的集群启动脚本。它们将启动 HA 群集。请注意,启动 Flink HA 集群前,必须启动 Zookeeper 集群,并确保为要启动的每个 HA 群集配置单独的 ZooKeeper 根路径。
示例:具有2个 JobManager 的 Standalone 集群
- 在conf/flink-conf.yaml 中配置高可用模式和 ZooKeeper quorum:
1 | high-availability: zookeeper |
- 在 conf/master 中配置 master:
1 | localhost:8081 |
- 在 conf/zoo.cfg 中配置 ZooKeeper 服务(目前,每台机器只能运行一个 ZooKeeper 进程)
1 | server.0=localhost:2888:3888 |
- 启动 ZooKeeper quorum:
1 | $ bin/start-zookeeper-quorum.sh |
- 启动 Flink HA 集群:
1 | $ bin/start-cluster.sh |
- 停止 Zookeeper quorum 和集群:
1 | $ bin/stop-cluster.sh |
六、YARN 集群的高可用性
在运行高可用性 YARN 集群时,我们不会运行多个 JobManager (ApplicationMaster) 实例,而只运行一个,该JobManager实例失败时,YARN会将其重新启动。Yarn的具体行为取决于您使用的 YARN 版本。
配置
Application Master最大重试次数(yarn-site.xml)
在YARN 配置文件 yarn-site.xml 中,需要配置 application master 的最大重试次数:
1 | <property> |
当前 YARN 版本的默认值是2(表示允许单个JobManager失败两次)。
Application Attempts(flink-conf.yaml):
除了HA配置(参考上文)之外,您还必须配置最大重试次数 conf/flink-conf.yaml:
1 | yarn.application-attempts: 10 |
这意味着在如果程序启动失败,YARN会再重试9次(9 次重试 + 1次启动)。如果 YARN 操作需要,如果启动10次作业还失败,yarn才会将该任务的状态置为失败。如果抢占,节点硬件故障或重启,NodeManager 重新同步等操作需要,YARN继续尝试启动应用。 这些重启不计入 yarn.application-attempts 个数中。重要的是要注意 yarn.resourcemanager.am.max-attempts 为yarn中程序重启上限。因此, Flink 中设置的程序尝试次数不能超过 YARN 的集群设置。
示例:高可用的YARN Session
1.配置 HA 模式和 ZooKeeper 集群在 conf/flink-conf.yaml 中:
1 | high-availability: zookeeper |
- 配置 ZooKeeper 服务在 conf/zoo.cfg 中(目前每台机器只能运行一个 ZooKeeper 进程):
1 | server.0=localhost:2888:3888 |
- 启动 ZooKeeper 集群:
1 | $ bin/start-zookeeper-quorum.sh |
- 启动 HA 集群:
1 | $ bin / yarn-session.sh -n 2 |
配置 Zookeeper 安全性
如果 ZooKeeper 使用 Kerberos 以安全模式运行,flink-conf.yaml 根据需要覆盖以下配置:
1 | zookeeper.sasl.service-name: zookeeper |
有关 Kerberos 安全性的 Flink 配置的更多信息,请参阅 此处。您还可以在 此处 找到关于 Flink 内部如何设置基于 kerberos 的安全性的详细信息。
Bootstrap ZooKeeper
如果您没有正在运行的ZooKeeper,则可以使用Flink程序附带的脚本。
这是一个 ZooKeeper 配置模板 conf/zoo.cfg。您可以为主机配置为使用 server.X 条目运行 ZooKeeper,其中 X 是每个服务器的唯一IP:
1 | server.X=addressX:peerPort:leaderPort |
该脚本 bin/start-zookeeper-quorum.sh 将在每个配置的主机上启动 ZooKeeper 服务器。 Flink wrapper 会启动 ZooKeeper 服务,该 wraper 从 conf/zoo.cfg 中读取配置,并设置一些必需的配置项。在生产设置中,建议您使用自己安装的 ZooKeeper。
